
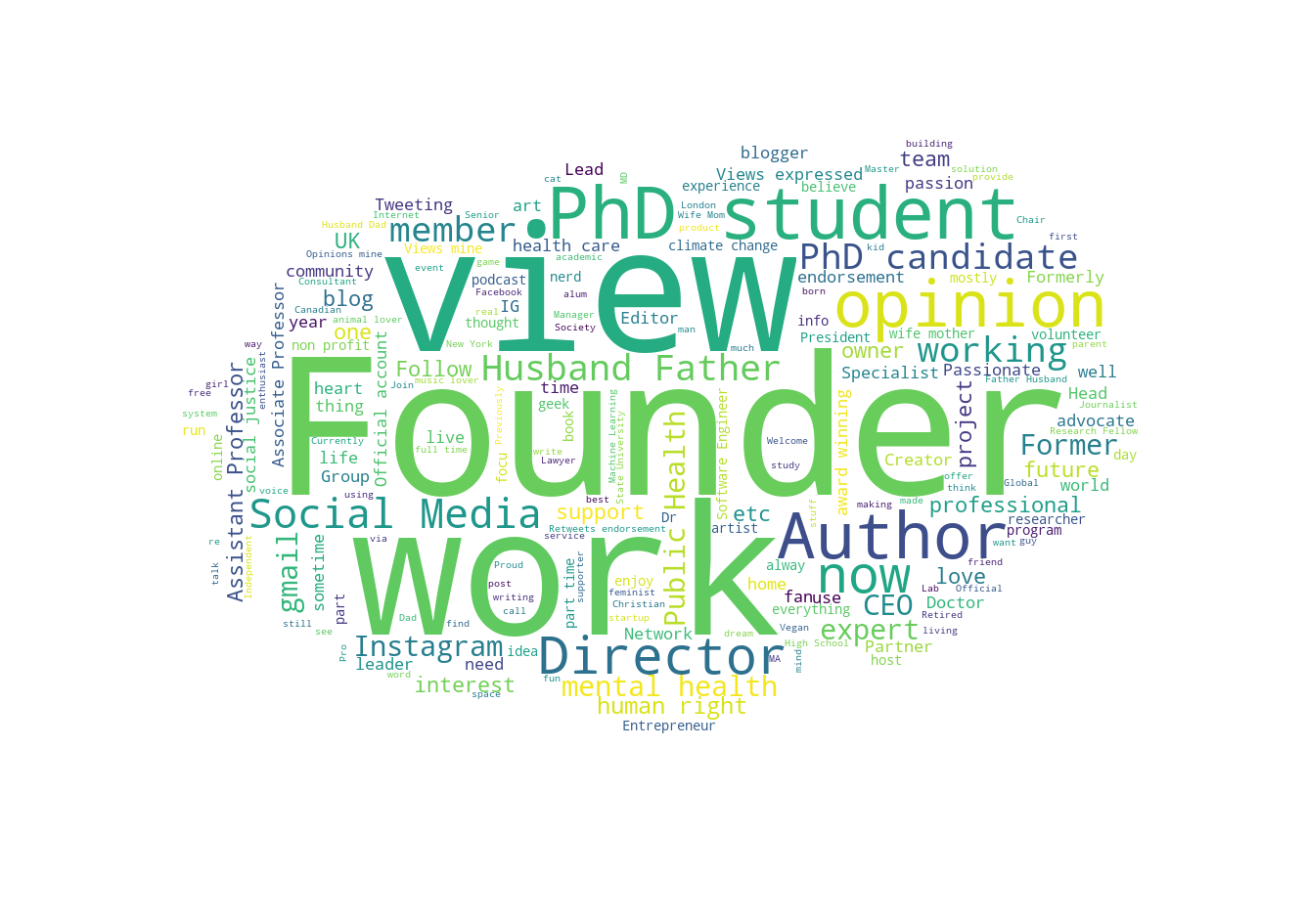
Just a quick post to display a word cloud I created as a demo for my Adv Programming students using the Python WordCloud module. I was surprised to find that “Founder” was the top occurring word in the profile descriptions. What does this tell us?
I first had to write a PHP script to grab all the tweet objects from Twitter Search API that were captured by Altmetric.com. I then stored all the unique author profiles in a separate table from the tweets, which gave me approximately 3.4 million unique Twitter users who tweeted about science as captured by Altmetric.com. Of these 3.4 million, there were approximately 2.8 million users who had some characters in their Twitter profile description field.
To return results from the description found in my MySQL table of author profiles, I used the following query because I wanted to remove hard returns and tabs from the profile descriptions.
SELECT REPLACE(REPLACE(REPLACE(TRIM(`description`), '\r', ' '), '\n', ' '), '\t', ' ')
FROM `profiles`
WHERE TRIM(`description`)!='';Next, we have the actual Python 3 code I used to create the WordCloud from the 2.8 million user descriptions. You’ll note I added a few extra terms to the STOPWORDS list because I ran this multiple times and found these terms that I wanted to remove from the final version.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
"""
Created on Sun Feb 10 16:19:56 2019
@author: tdbowman
"""
import io
import csv
import numpy as np
from wordcloud import WordCloud, STOPWORDS
from os import path
from PIL import Image
# current directory
currdir = path.dirname(__file__)
# from https://github.com/nikhilkumarsingh/wordcloud-example/blob/master/mywc.py
def create_wordcloud(text):
# use cloud.png as mask for word cloud
mask = np.array(Image.open(path.join(currdir, "cloud.png")))
# create set of stopwords
stop_words = ["https", "co", "RT", "del", "http",
"tweet", "tweets", "twitter", "en", "el", "us", "et",
"lo", "will", "ex", "de", "la", "rts"] + list(STOPWORDS)
# create wordcloud object
wc = WordCloud(background_color="white",
max_words=200,
mask=mask,
stopwords=stop_words)
# generate wordcloud
wc.generate(text)
# save wordcloud
wc.to_file(path.join(currdir, "wc.png"))
if __name__ == "__main__":
# Grab text from file and convert to list
your_list = []
with io.open('all_descriptions.csv', 'r', encoding='utf-8') as f:
reader = csv.reader(x.replace('\0', '') for x in f)
your_list = ','.join([i[0] for i in reader])
# generate wordcloud
create_wordcloud(your_list)It could use some cleanup and the image could be higher resolution, but it’s a good example for the students how to utilize Python to create a word cloud.